
Research Identity
Bowen Jing (荆博闻) is a researcher in Generative AI and Embodied Intelligence.
My research focuses on generative world models for embodied agents. I study how diffusion-based generative models can model and simulate complex interactive environments, enabling intelligent agents to reason, predict, and act in the physical world.
My work lies at the intersection of:
- Generative Models: diffusion, video generation, and structured generative modeling
- World Models: learning environment dynamics, future prediction, and simulation
- Embodied Intelligence: agents that perceive, reason, and plan through interaction
- Autonomous Driving and Robotics: real-world applications for decision-making systems
My long-term goal is to develop AI systems that understand and interact with the real world, moving beyond perception toward intelligence grounded in physical environments.
Currently, I am seeking a PhD opportunity to work on generative world models, embodied intelligence, and diffusion-based simulation for robotics and autonomous systems.
Google Scholar • GitHub • LinkedIn
Research Theme
Generative AI -> World Models -> Embodied Intelligence
My central research question is:
How can generative models learn the dynamics of the real world and support intelligent decision-making for embodied agents?
I am particularly interested in three directions:
-
Generative World Models
Using diffusion and generative models to capture complex environment dynamics for scene generation, future prediction, interaction modeling, and simulation.
-
Counterfactual Reasoning
Building models that can answer questions such as what would happen if an agent behaved differently? This is important for safety evaluation, decision analysis, and scenario reasoning.
-
Embodied Intelligence
Applying generative world models to autonomous driving, robotics, and interactive agents, with the goal of enabling long-horizon planning in real-world environments.
Research Philosophy
My research is guided by first-principles thinking. I am interested in foundational questions such as:
- What is an environment?
- What is intelligence?
- What is decision-making?
By combining ideas from cognitive science, generative modeling, and causal reasoning, I aim to study how AI systems can form internal models of the world and use them to support prediction, interaction, and planning.
Long-term Vision
To build AI systems that can model, understand, and interact with the real world, enabling the emergence of general intelligence grounded in physical environments.
This vision goes beyond perception, image generation, or language reasoning alone. The goal is to build systems that can predict the future, reason about causality, interact with environments, and make decisions under real-world dynamics.
🔥 News
- 2025.11: 🏆 Our work StyleDrive has been accepted as an Oral presentation at AAAI 2026.
- 2025.10: 🏆 Our work StyleDrive received an average score of 7 in the AAAI 2026 review process!
- 2025.08: 🤖 Joined Tuojing Intelligence as a Researcher, focusing on diffusion-based scenario generation and embodied AI.
- 2025.02: 🎓 Joined Tsinghua AIR (Institute for AI Industry Research) as a Research Assistant, working on generative modeling for autonomous driving.
- 2025.07: 🚀 Our paper “StyleDrive: Towards Driving-Style Aware Benchmarking of End-to-End Autonomous Driving” is now on arXiv! Read here
- 2024.09: 🎉 Graduated from The University of Manchester (MSc AI, Distinction)
- 2023.07: 🎓 Completed BSc Computer Science at The University of Manchester
📝 Publications
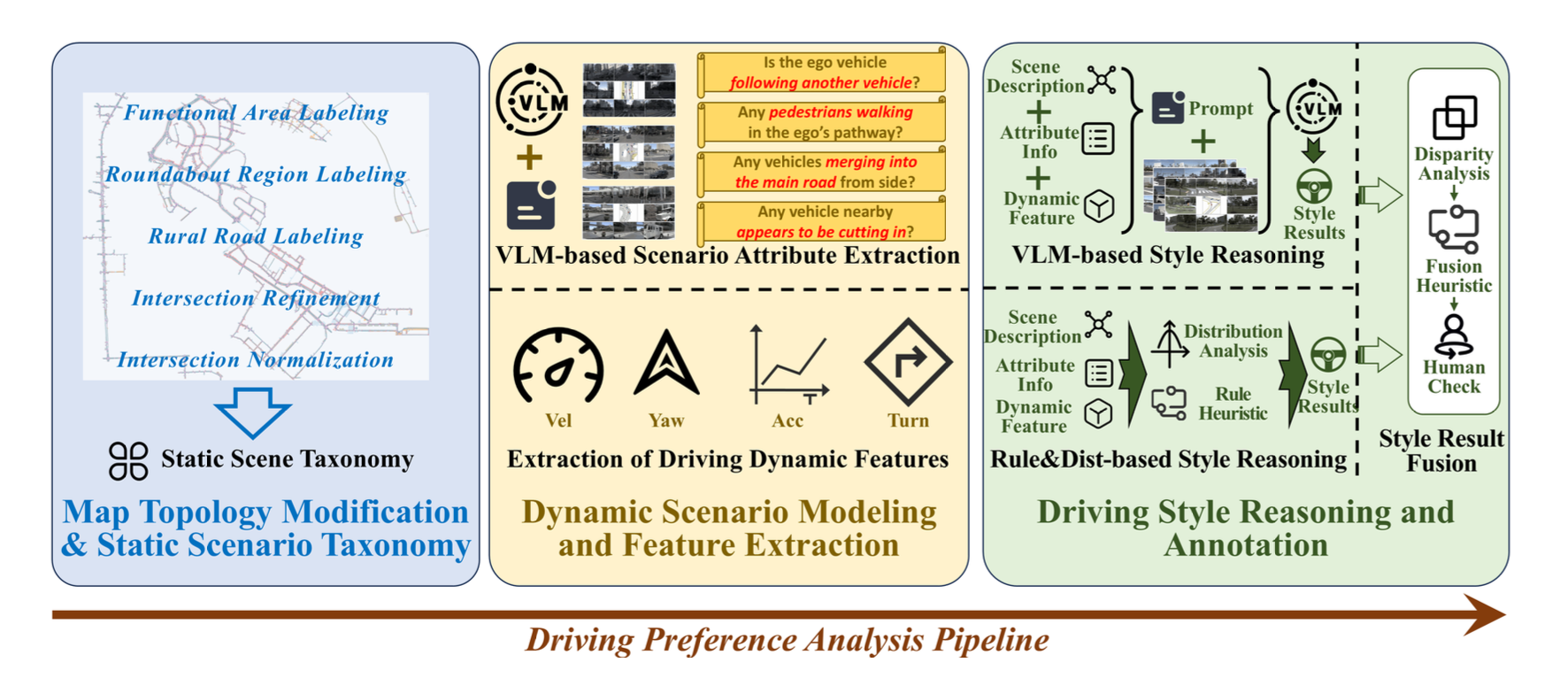
StyleDrive: Driving-Style Aware Benchmarking of End-to-End Autonomous Driving
Ruiyang Hao, Bowen Jing, Haibao Yu, Zaiqing Nie
- 🚗 Introduced the first large-scale real-world dataset for driving-style–aware E2E autonomous driving.
- 🧠 Developed a hybrid annotation pipeline combining motion heuristics and VLM reasoning.
- 📊 Proposed the SM-PDMS metric and established the first benchmark for personalized E2EAD.
- 💡 Achieved notable improvements in human-like driving through style conditioning.
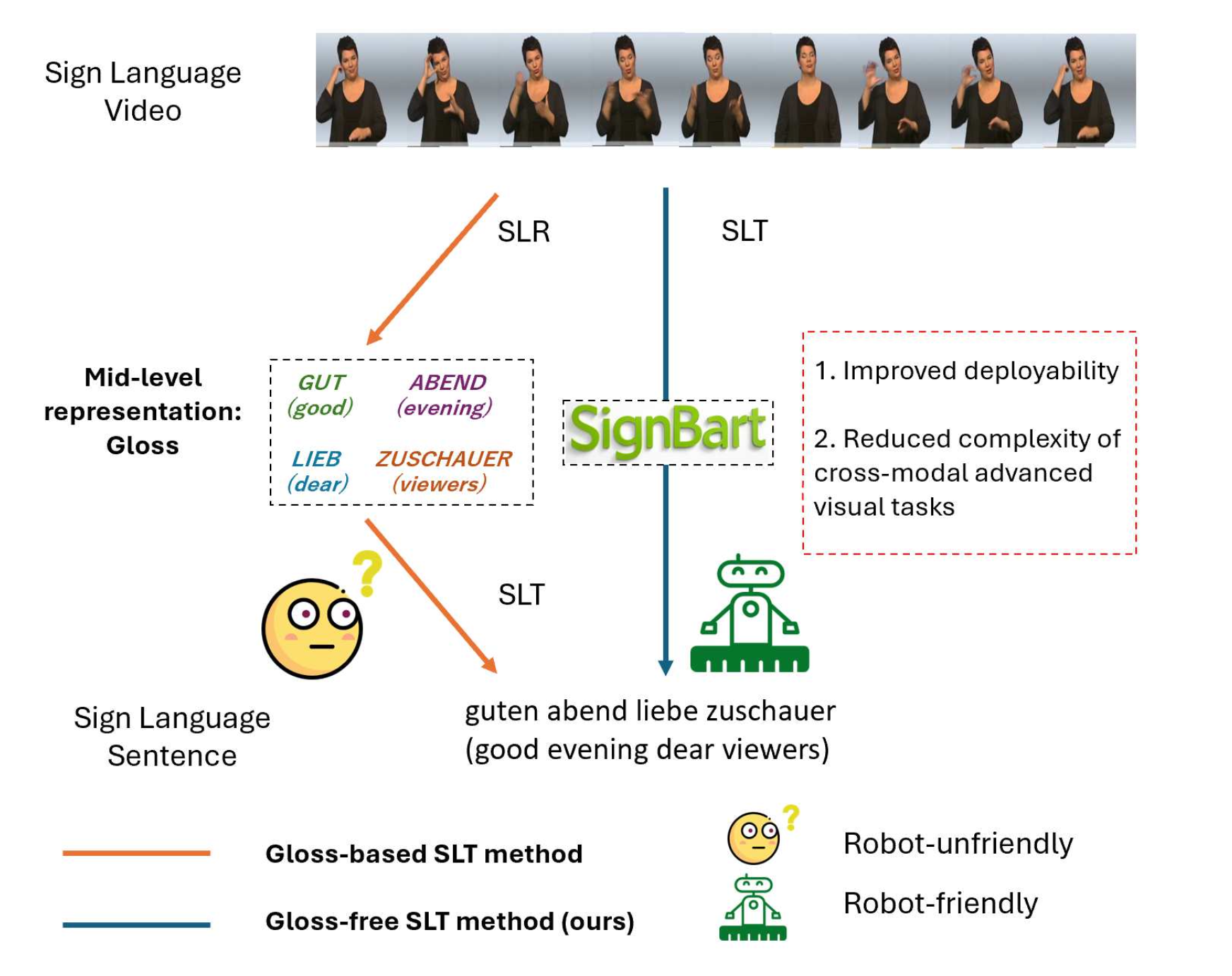
[SignBart: Gloss-Free Sign Language Translation for Human-Robot Interaction via Efficient Spatiotemporal Learning]
Hongpeng Wang, Bowen Jing, Hao Tang, Xiang Li, Fanying Kong
[Preprint (Submitted to ICRA 2026)]
- 🧏♂️ Introduced a gloss-free, end-to-end sign language translation framework for human–robot interaction.
- ⚙️ Designed a lightweight visual encoder (CSIFE-ConvNeXt) achieving 58% parameter reduction.
- 🧠 Proposed TTT-mBART, enabling test-time adaptation and robust domain transfer.
- 📈 Achieved state-of-the-art results on PHOENIX-2014T and CSL-Daily benchmarks.
- 🤖 Demonstrated strong deployability for assistive and service robots in real-world settings.
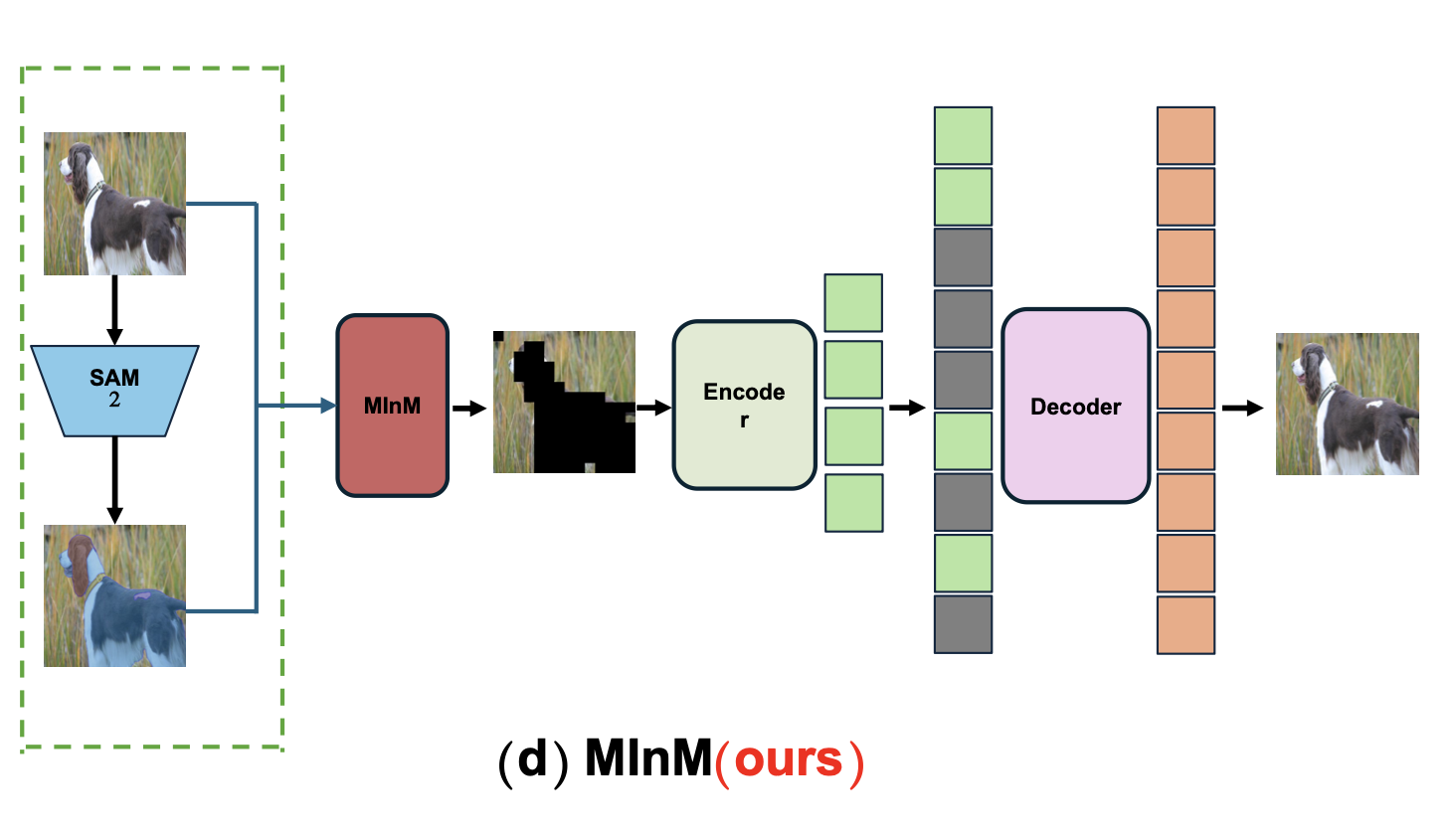
[MInM: Mask Instance Modeling for Visual Representation Learning] Bowen Jing
[Preprint (Submitted to AAAI 2026)]
- Proposed an instance-aware masked image modeling framework (MInM) that replaces random masking with SAM2-generated semantic masks to guide self-supervised learning.
- Integrated MInM into the MAE pipeline with zero architectural change, improving convergence speed and semantic alignment.
- Evaluated on ImageNet-1K, Pascal VOC 2007, MS COCO, and MedMNIST; demonstrated better semantic generalization and downstream transfer.
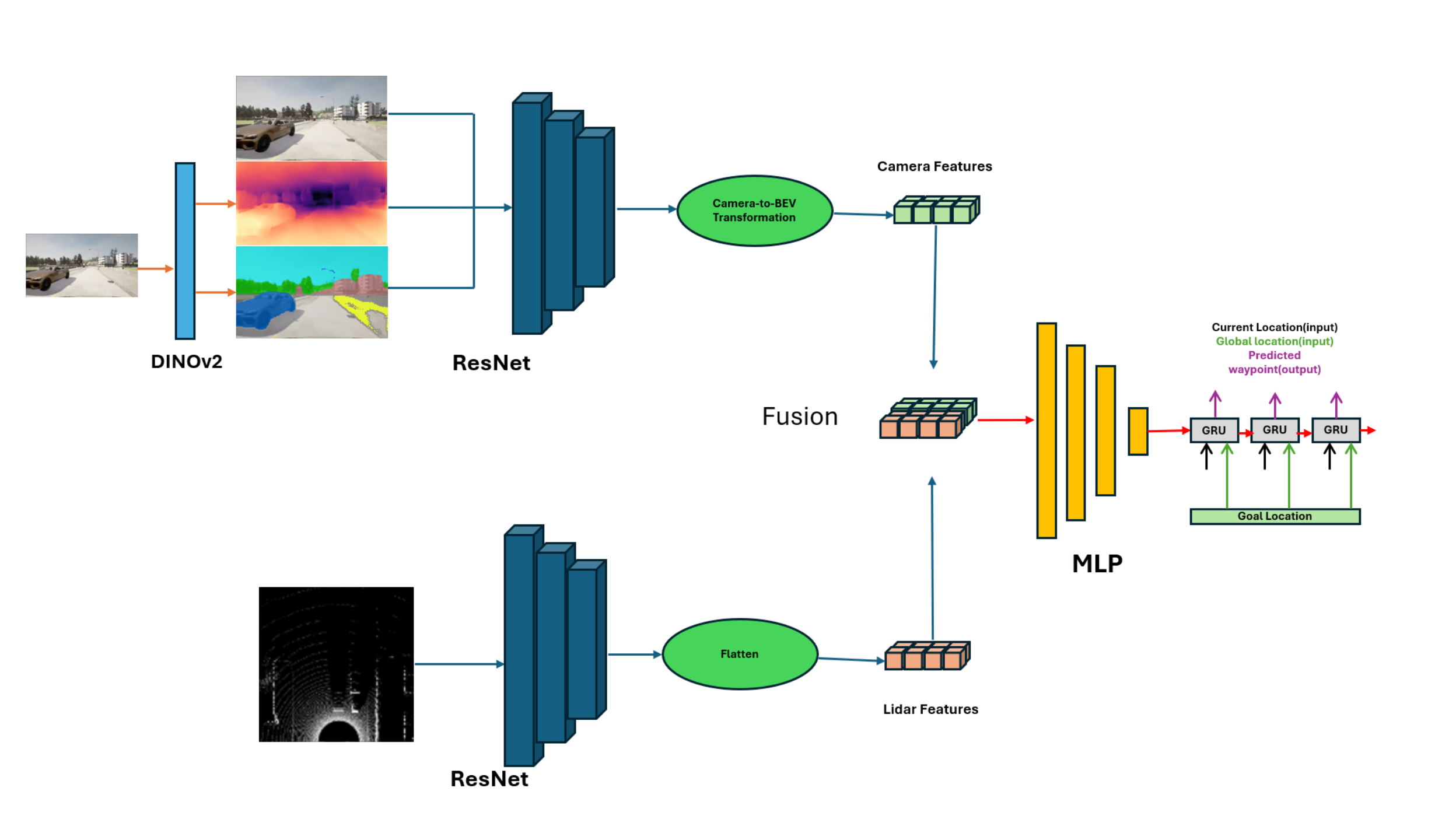
End-to-End Autonomous Driving System with Middle Fusion and Attention
Bowen Jing
- Built a multimodal AV system integrating LiDAR and RGB via channel-attentive fusion.
- Deployed in CARLA and validated via extensive ablation studies.
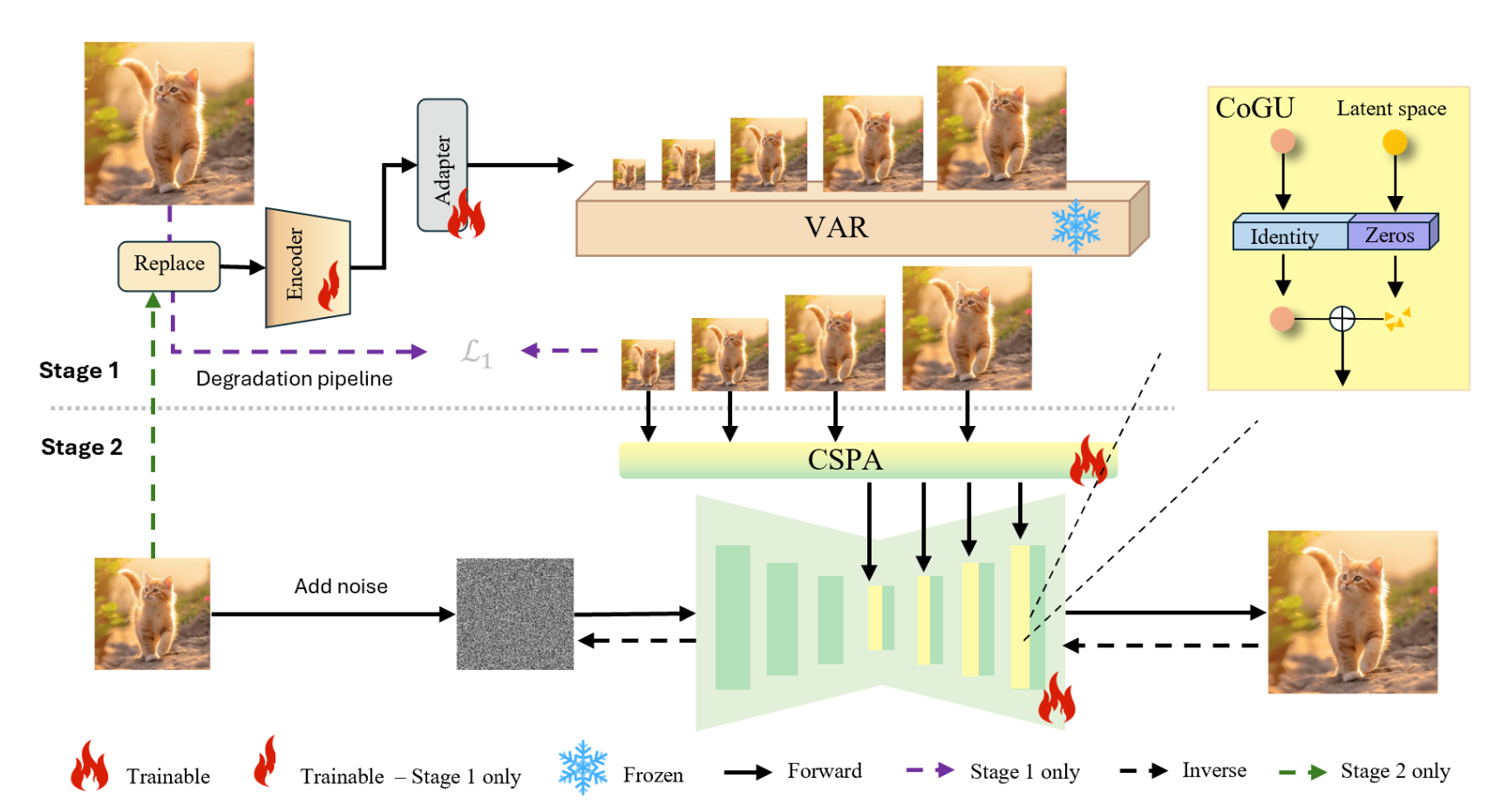
[VDiff-SR: Diffusion with Hierarchical Visual Autoregressive Priors for Image Super-Resolution]
- Proposed a novel hybrid framework combining diffusion models and pretrained Visual AutoRegressive (VAR) priors for real-world image super-resolution (Real-ISR).
- Designed two new modules: Condition-Gated Unit (CoGU) for feature conditioning, and Cross-Scale Prior-Aligned Attention (CSPA) for multi-scale structural alignment.
- Achieved SOTA performance on RealSR and RealSet5 with significant improvements in perceptual metrics (CLIP-IQ ↑, MUSIQ ↑).
- Conducted detailed ablation demonstrating the synergy of VAR priors and denoising-based generation.
📖 Educations
- 2023.09 – 2024.09, MSc in Artificial Intelligence, University of Manchester
- Focus: Deep Learning, Computer Vision, Reinforcement Learning, Robotics
- Dissertation: Comparative study of Deep Learning and Traditional Vision in Robotic Perception
- Graduated with Distinction (Top 10%)
- 2020.09 – 2023.06, BSc in Computer Science, University of Manchester
- Specialized in software development and machine learning foundations
- Final Year Project: Spiking Neural Network
💻 Internships
- 2025.08 – Present · Tuojing Intelligence — Research Intern in Traffic Simulation and Generative Modeling
- 2025.02 – 2025.08 · Tsinghua University, AIR — Research Intern in Large-Scale Autonomous Driving Data Mining